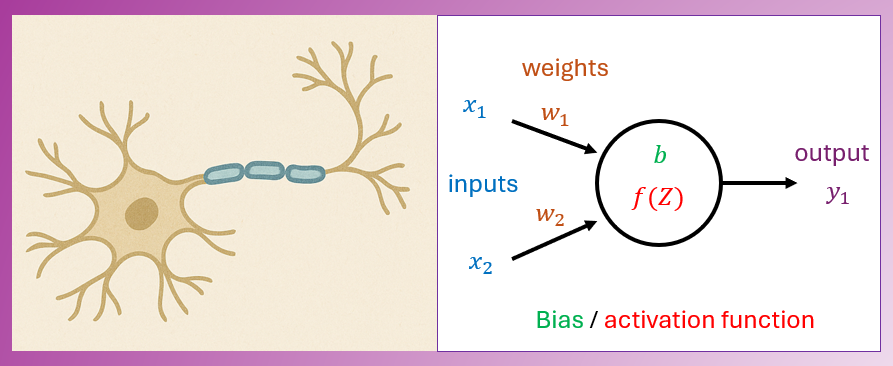
1 Dendrittene - grenene som lytter

Kiara la hånden på en av de mange grenene. «Se på disse grenene. De er som dendritter. Dendrittene er den delen av et nevron som mottar signaler fra andre nevroner. De er som ører — de hører alt rundt seg.» Liora lente seg mot treet og hvisket, «Hallo?» «Akkurat,» sa Kiara. «Nevroner hvisker til hverandre også — men med ørsmå elektriske signaler.»